Git Status Internals
For win-git-status, I reached the point where I wanted to compare the
working tree files to the git index. I understood that git used sha1 for
versioning the contents of files, as well as other parts of a git repo (the
“internals” chapter of the git-book discusses the use of sha1 better.).
So I decided to try and perform the sha1 hash on every file in the working
tree. The time to hash quickly became a large bottle neck. I was using
0f9f0a40 from the llvm-project which had 97912 files. I killed the
process after 30 seconds. git status only takes 0.340 seconds when run on
the commit 0f9f0a40.
I had mentioned in Efficientlly Walking File Directories in Rust
how I should look into the actual git status implementation, it seemed that
now was the time.
How libgit2 Does Status
I already had a clone of version 1.1.0 of libgit2 available and built.
libgit2 provides an example status command that provides basic git
status functionality, but doesn’t fully mimic it. With the libgit2
examples built I was able to debug how the command worked.
I created a simple repo with one file:
mkdir simple_repo
cd simple_repo
git init
echo "some text" > foo.txt
git add foo.txt
git commit -m "committing one file"
This simple repo allowed be to minimize the debugging effort. I mean who want’s to walk through 90k file entries?
Git File Hashing Detour
Since I had the repo created with minimal values I decided to test out my
understanding of how file contents are hashed. I know that on windows
machines, one usually has core.autocrlf set to true and this setting can
affect the hash. I had intentionally not put any kind of line continuation in
the example file foo.txt so I should be able to avoid that nuance.
To test out my understanding I first determined what git said the hash was. (If I did the example correctly you should get the same result.):
$ git ls-tree HEAD
100644 blob 7b57bd29ea8afbdeb9bac64cf7074f4b531492a8 foo.txt
So git hashed the file to 7b57bd29ea8afbdeb9bac64cf7074f4b531492a8. I next
tried to hash the file directly:
$ sha1sum foo.txt
a5c341bec5c89ed16758435069e3124b3685ad93 *foo.txt
Clearly these aren’t the same hash. Scratching my head for a bit I decided to hash the object that git had stored.
Git will store objects in .git/objects. The first 2 characters of the hash
value will be the directory and the remaining will be the stored object. The
objects are stored in a compressed format so if one cats them or similar it
will be binary gibberish.
$ sha1sum .git/objects/7b/57bd29ea8afbdeb9bac64cf7074f4b531492a8
4513c89020c6f389db9e7ad6523a2d4fd2805ede *.git/objects/7b/57bd29ea8afbdeb9bac64cf7074f4b531492a8
So now I’m left with neither the raw file nor the stored object matching the hash that git reports it as. At this point I did some googling and found that git stores a header with object and that’s included in the hash. Really I should have just re-read the git objects section of the git-book as it says it plain as day.
Git concatenates the header and the original content and then calculates the SHA-1 checksum of that new content.
So to test this out I edited foo.txt to include the header:
$ echo -e "blob 10\0some text" > foo.txt
$ sha1sum foo.txt
7b57bd29ea8afbdeb9bac64cf7074f4b531492a8 *foo.txt
Victory!!! At least now I’m more familiar with how git is hashing files.
Debugging libgit2
I wanted to debug how libgit2 was able to hash so many files so fast, when I had to kill my process after 30 seconds, with no end in sight.
When debugging anything, I usually try to start at one end or the other of
the execution path. I’m familiar enough with libgit2 that I knew
git_status_list_new() was going to be the start of the status logic. I felt
that the start of the execution path might be too broad of an area to focus
on. So instead I search for sha in the libgit2 repo and found
git_hash_sha1_update(). git_hash_sha1_update() has multiple
implementations depending on compiler settings/platform so I decided to set a
breakpoint in git_hash_update() where it called git_hash_sha1_update() to
ensure I didn’t miss the occurrence.
int git_hash_update(git_hash_ctx *ctx, const void *data, size_t len)
{
switch (ctx->algo) {
case GIT_HASH_ALGO_SHA1:
return git_hash_sha1_update(&ctx->sha1, data, len); // breakpoint here
default:
assert(0);
return -1;
}
}With the break point set it was time to debug. Looking at the call stack of the first few hits, it appeared to be the config file, so seemed irrelevant.
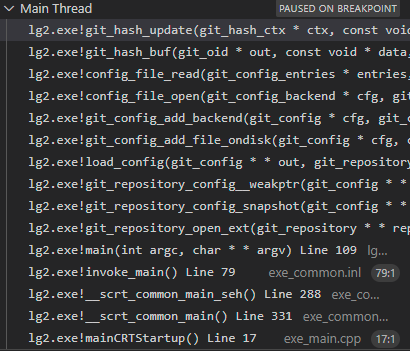
It wasn’t until the 5th time hitting the breakpoint that it looked like a possibility.
Looking more closely at the call stack one can see the function git_reference_peel(). Jumping to the invocation location one can see:
if ((error = git_reference_peel(&obj, head, GIT_OBJECT_TREE)) < 0)
goto cleanup;This doesn’t look like the hashing of foo.txt it appears to be looking up
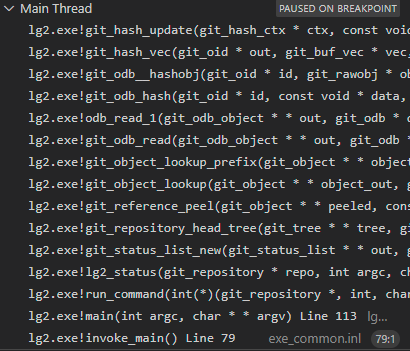
the tree for the current head. I let the break point advance a couple more
times and hit an instance where it looked like the behavior was looking up
the current commit. Then the process just finished.
I was at a loss, libgit2 never seemed to be hashing foo.txt during the
status operation. So how did libgit2 know if foo.txt was modified or not?
Jumping to the Other Side of the Execution
Since it appeared that libgit2 was never hashing the on disk version of
foo.txt, it was time to figure out what libgit2 was doing to compare the
on disk version to the repo version.
Scrutinizing git_status_list_new(), there is a call to git_index_to_work_dir(). This seemed like a likely candidate to debug into. Inside git_index_to_work_dir() there is a block that looks to actually perform the comparison between the index and workdir, by use of git_diff__from_iterators().
if ((error = diff_prepare_iterator_opts(&prefix, &a_opts, GIT_ITERATOR_INCLUDE_CONFLICTS,
&b_opts, GIT_ITERATOR_DONT_AUTOEXPAND, opts)) < 0 ||
(error = git_iterator_for_index(&a, repo, index, &a_opts)) < 0 ||
(error = git_iterator_for_workdir(&b, repo, index, NULL, &b_opts)) < 0 ||
(error = git_diff__from_iterators(&diff, repo, a, b, opts)) < 0)
goto out;It may be good to stop and discuss a little bit about how git_diff__from_iterators() appears to work. It looks like it compares the sorted version of each directory in the index and working tree. This sorted approach allows it to quickly see when a file is extra in the index or the working tree. When a file exists in the index, but not in the working tree, it is in a deleted state. When a file exists in the working tree but not the index, it is in an untracked.
The important code block to notice in git_diff__from_iterators() is when a file name exists in both the index and working tree.
/* otherwise item paths match, so create MODIFIED record
* (or ADDED and DELETED pair if type changed)
*/
else
error = handle_matched_item(diff, &info);Debugging into handle_matched_item() one quickly walks into
maybe_modified(). maybe_modified() was the function I was looking for. I
probably walked the debugger through this function 10 times with foo.txt
not modified and it modified in different ways to try and understand what was
going on.
The important thing to take away here is the following clause:
/* if we have an unknown OID and a workdir iterator, then check some
* circumstances that can accelerate things or need special handling
*/
} else if (git_oid_is_zero(&nitem->id) && new_is_workdir) {The OID is “Object ID” it’s usually the hash value of an object. So when
one is comparing the working tree (workdir iterator) one doesn’t know what
the OID is. If one looks further in that condition you can see that it
compares the file metadate of the index version and the working tree version.
And only if there is an mtime change, or similar, with the same file size
will a working version of the file actually get hashed.
How Git Does Status
I didn’t debug how git itself compares files for the git status operation.
After what I discovered debugging libgit2, I decided to just quickly jump
around the git code base looking for what appeared to be similar logic as
libgit2. I eventually found diff_filespec_check_stat_unmatch(). This
function looks to be doing similar logic by comparing file size and mode.
Summary
My assumption that git status was hashing the working directory files in
order to compare them to the index was completely incorrect. Git will take
the more optimil approach and initially compare the file metadata. Only when
the file size is the same and the other metadata is different will git
perform a hash on a working tree version of a file.
As mentioned in Efficientlly Walking File Directories in Rust, I’m looking at using jwalk. jwalk parallelizes per directory. If I do it correctly I should be able to use a similar directory comparison as libgit2 while on those separate threads. Not sure if that will provide any extra speed up, but it may actually be the simpler implementation.