Using a Batch Exporter
In the previous post we discovered
that using the
SimpleSpanProcessor
resulted in 4-10ms that happens after inside_step_1 completes.
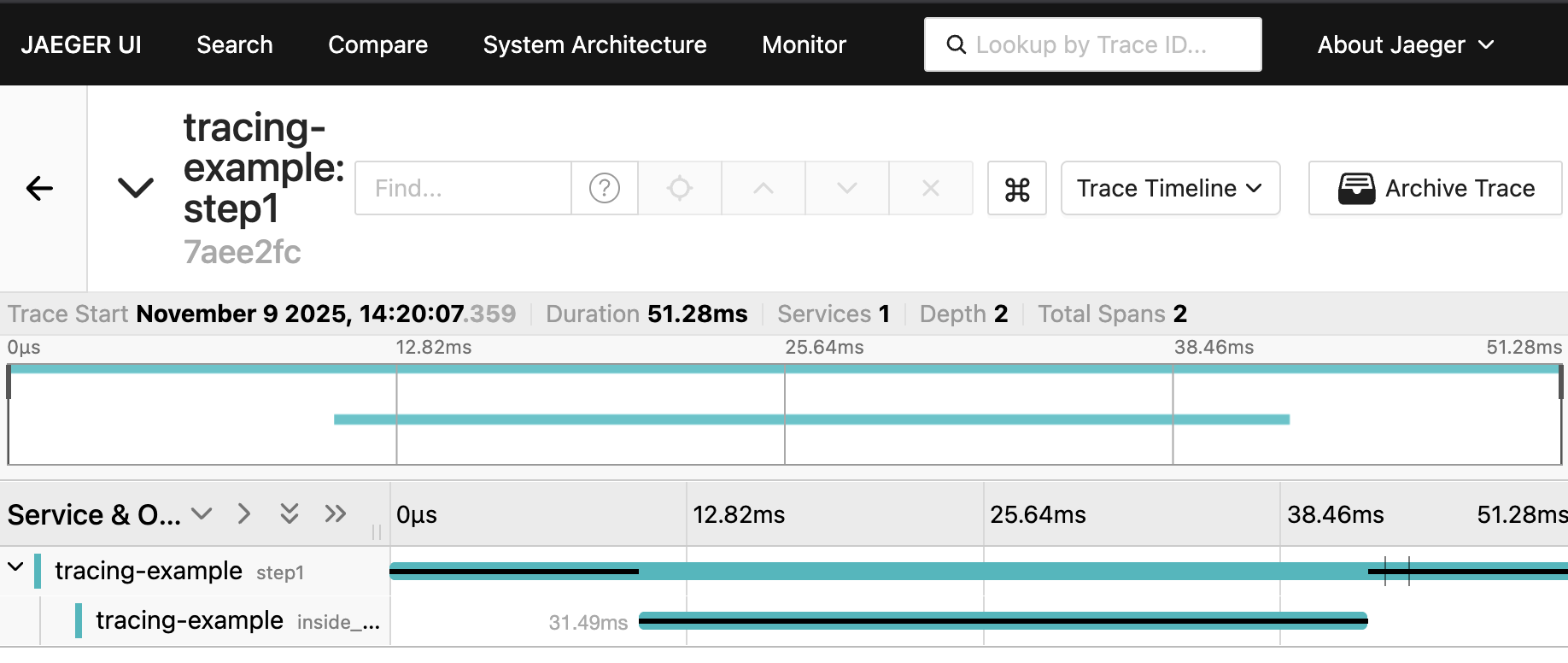
The simple exporter was used in the example, as it was simple to setup and didn’t require any extra steps to get spans published. However, moving forward I don’t want the extra time to be interpreted as a downside to using tracing in rust. So we’re going to move over to the BatchSpanProcessor
Per the documentation:
[BatchSpanProcessor] uses a dedicated background thread to manage and export spans asynchronously
This means that the running task will pass the spans onto this other thread and the other thread will handle the overhead of sending the spans to Jaeger.
In order to use a BatchSpanProcessor one needs to change how the provider is
built and be sure to call
shutdown()
on the provider.
The documentation for the SDKTraceProvider says
When the last reference is dropped, the shutdown process will be automatically triggered to ensure proper cleanup.
I have not found this auto cleanup to be true. If one doesn’t explicitly call
shutdown(), then no traces seem to get to Jaeger for this simple example.
Below is the updated main using
with_batch_exporter()
instead of
with_simple_exporter(). Notice that the provider now needs to be cloned() into the
set_trace_provider(). This is so we can keep it around to shutdown() at the
end.
fn main() -> Result<(), Box<dyn std::error::Error>> {
let exporter = opentelemetry_otlp::SpanExporter::builder()
.with_http()
.with_protocol(Protocol::HttpJson)
.build()?;
let resource = Resource::builder()
.with_service_name("tracing-example")
.build();
let provider = opentelemetry_sdk::trace::SdkTracerProvider::builder()
.with_resource(resource)
.with_batch_exporter(exporter)
.build();
opentelemetry::global::set_tracer_provider(provider.clone());
step1();
step2();
Ok(provider.shutdown()?)
}
Running this updated version should result in a trace similar to:
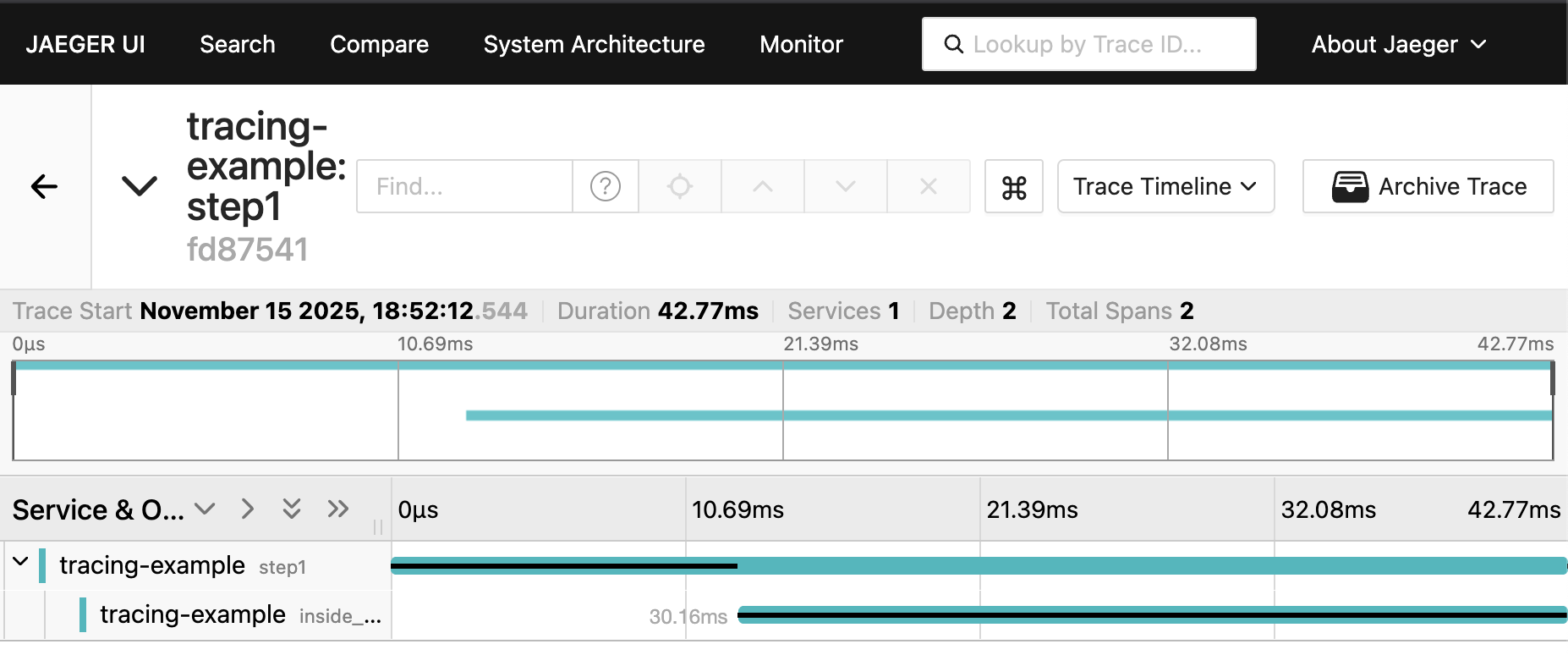
We now see almost no time in step1 after inside_step1 finishes. This is
because the span is sent to the batch processing thread, which is significantly
faster than sending directly to Jaeger on span completion.
Using the batch processor should now provide the minimal overhead for tracing one would hope to get in a real world application.